Diese Seite ist die HTML-Version der Ausarbeitung meines Yacc-Vortrages im Seminar Software-Entwicklungswerkzeuge.
I. Was ist Yacc?
I.1 Was ist Yacc?
YACC ist ein Parser-Generator, d.h. ein Programm, mit dem man Parser erstellen kann. Es wurde in den frühen 70er Jahren von S. C. Johnson entwickelt und steht inzwischen auf allen UNIX-System zur Verfügung. Die Abkürzung YACC steht für "yet another compiler-compiler", was andeutet, daß ein Einsatzzweck von YACC auch die Entwicklung von Compilern ist, es kann jedoch überall da eingesetzt werden, wo Programme Texteingaben einlesen müssen. Dies ist in sehr vielen Anwendungen der Fall, wie z.B. beim Einlesen von Konfigurationsdateien oder auch beim Umsetzen von Kommunikationsprotokollen (z.B. TCP/IP oder HTTP). Seine Stärke zeigt YACC vor allem da, wo diese Eingaben sehr vielseitig und unterschiedlich ausfallen.
Als Eingabe erwartet YACC eine Datei, die eine sogenannte Grammatik (ähnlich der Backus-Naur-Form) enthält. Diese Grammatik stellt die Beschreibung des Regelwerks für den Parsers dar, den man generieren will. Der Parser kann Strukturen, die diesen Regeln folgen, erkennen und definierte Aktionen ausführen.
YACC erzeugt aus dieser Grammatik ein C-Quellprogramm, welches den vollständigen Parser enthält.
I.2 Wie kann man Yacc benutzen?
Zur Benutzung von YACC ein einfaches Beispiel: Angenommen, man hat eine Grammatik erstellt, die sich in der Datei grammar.y befindet (die Dateiendung .y ist Konvention für YACC-Quelldateien). Man ruft YACC mit yacc grammar.y auf und erhält die Ausgabedatei y.tab.c, den C-Quellcode des Parsers für die Grammatik grammar.y. Diesen kann man dann mit einem beliebigen C-Compiler übersetzen, z.B. mit cc y.tab.c. Man erhält dann die ausführbare Datei a.out, die den fertigen, ausführbaren Parser enthält.

II. Die Syntax von Yacc
II.1 Grundsätzliche Funktionsweise des Parsers
Der von YACC erzeugte Parser arbeitet mit verschiedenen Arten von Symbolen. Diese teilen sich auf in Terminal- und Nicht-Terminalsymbole, und Terminalsymbole kännen wiederum entweder Literale oder Tokens sein.
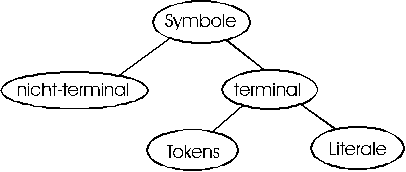
Literale sind einzelne Zeichen, also Buchstaben, Ziffern oder andere Zeichen. Tokens kännen im Gegensatz zu Literalen auch aus mehreren Zeichen bestehen oder eine ganze Klasse von Zeichen wie z.B. Ziffern darstellen, sie sind sozusagen eine allgemeinere Form von Terminalsymbolen als Literale. Terminalsymbole sind die kleinsten Einheiten, mit denen der Parser umgehen kann.
Nicht-Terminalsymbole bestehen aus einem oder meistens aus mehreren Terminalsymbolen. Ein Terminalsymbol kännte beispielsweise eine Zahl oder ein mathematischer Operator sein, ein Nicht-Terminalsymbol ein ganzer Ausdruck, der aus Zahlen und Operatoren besteht.
Der Parser besteht aus zwei wichtigen und ein paar weniger wichtigen Teilen, die als Funktionen realisiert werden.
Die erste Funktion ist yylex(), die die Aufgabe eines Scanners übernimmt. Der Scanner liest die Eingabe des Parser Zeichen für Zeichen ein und wandelt sie in einen Strom von Tokens um. Er liefert pro Aufruf nicht alle Tokens auf einmal, sondern immer nur das nächste Token. Alle Tokens müssen natürlich vorher definiert werden. Wenn ein Zeichen nicht als Token identifiziert werden kann, wird es direkt als Literal übergeben (Grundsätzlich ist es empfehlenswert, alle oder mäglichst viele Eingabesymbole als Tokens zu definieren, dadurch wird die Aufgabe der Literalerkennung vom Parser an den Scanner delegiert. Dies hat den Vorteil, daß als Tokens deklarierte Literale bei Änderungen nur einmal im Scanner geändert werden müssen, anstatt daß jedes Vorkommen des Literals in der Grammatik überprüft und geändert werden muß). Am Ende der Eingabe steht das vordefinierte Ende-Token $end, das den Wert 0 oder einen negativen Wert hat. Die Scanner-Funktion liest also Zeichen ein, erkennt daraus das entsprechende Token oder Literal und gibt dessen Typ als Integerwert zurück. Der eigentliche Inhalt des Tokens, also zum Beispiel bei einem Zahl-Token der Wert der Zahl oder ein String bei einem Text-Token, wird in der globalen Variable yylval übergeben.
Die Funktion yylex() kann man selbst als C-Quelltext in das YACC-Programm schreiben, oder mit Hilfe von LEX generieren (vgl. auch Kapitel V sowie den vorherigen Vortrag über LEX ).
Die zweite wichtige Funktion ist yyparse(), der eigentliche Parser. Dies ist der Teil des Programms, der von YACC erzeugt wird. Diese Funktion ruft immer wieder den Scanner auf, um das nächste Token, das sogenannte Vorgriffs-Token (engl. "lookahead-token") einzulesen. Auf den so nach und nach entstehenden Tokenstrom werden die in der Parsergrammatik anzugebenden Grammatikregeln angewendet. Solch eine Regel kännte zum Beispiel im Klartext lauten: "Ein Ausdruck besteht aus einer Zahl oder einem Ausdruck, einem Operator und noch einem Ausdruck." Die Tokens sind hier Zahl und Operator, Ausdruck ist ein Nicht-Terminalsymbol. Wenn sie in der Reihenfolge Zahl Operator Zahl auftreten, kännen sie nach der Regel zu Ausdruck Operator Ausdruck und wieder zu Ausdruck reduziert werden, d.h. die Tokens Zahl Operator Zahl werden in zwei Schritten durch das Token Ausdruck ersetzt. Gleichzeitig kännen noch C-Aktionen definiert werden, die bei der Abarbeitung der Regel ausgeführt werden. All dies wird später an einem Beispiel besser ersichtlich werden.
Außerdem benötigt man noch ein Hauptprogramm, das einfach nur den Parser yyparse() aufruft. Dies geschieht in C in der Funktion main(). Man kann sie selbst schreiben oder aus der YACC-Bibliothek einbinden, indem man den von YACC erzeugten C-Quelltext mit der C-Compileroption -ly compiliert, also z.B. cc y.tab.x -ly. Dort stehen auch einige andere Funktionen wie z.B. die Fehlerbehandlungsfunktion yyerror(), auf die in Kapitel II.6 noch eingegangen wird.
Der einzulesende Text wird vom Scanner in Terminalsymbole, also in Tokens und Literale aufgeteilt. Diese werden vom Parser durch Anwendung der Grammatikregeln solange zu Nicht-Terminalsymbolen zusammengefaßt, d.h. reduziert, bis die gesamte Eingabe verarbeitet wurde und nur noch ein Symbol (das Startsymbol) übrigbleibt oder ein Fehler aufgetreten ist. Man nennt dieses Vorgehen Bottom-Up-Prinzip, da die Grammatikregeln quasi von unten nach oben abgearbeitet werden. Die umgekehrte Methode heißt dementsprechend Top-Down-Strategie. Dort werden Nicht-Terminalsymbole solange ersetzt, bis nur noch Terminalsymbole übrigbleiben. Dies hat jedoch gegenüber der Bottom-Up-Methode den Nachteil, daß mehrere Tokens auf einmal eingelesen werden müssen und eventuell ein sogenanntes "Backtracking" notwendig wird. (Näheres dazu im Vortrag über PCCTS).
Das Startsymbol muß nicht-terminal sein, und alle anderen Symbole müssen sich von ihm aus erreichen lassen, d.h. jedes andere Symbol muß sich in irgendeiner Form alleine oder zusammen mit anderen Symbolen zu dem Startsymbol reduzieren lassen. Außerdem müssen alle nicht-terminalen Symbole durch Grammatikregeln definiert werden, sie müssen also mindestens einmal auf der linken Seite einer Regel stehen.
II.2 Aufbau eines Yacc-Quellprogramms
Ein YACC-Quellprogramm besteht aus einem Deklarationsteil, einem Teil mit den eigentliche Grammatikregeln und einem Teil mit zusätzlichen Funktionen. Im Deklarationsteil stehen neben den eigentlichen YACC-Deklarationen optional auch einige C-Deklarationen Die drei Abschnitte werden durch doppelte Prozentzeichen (%%) voneinander getrennt:
%{
C-Deklarationen
%}
YACC-Deklarationen
%%
Grammatikregeln
%%
Zusätzlicher C-Quellcode, z.B. yylex()
Die Deklarationen sowie der Funktionsteil sind optional, ein YACC-Quellprogramm besteht also mindestens aus den Grammatikregeln:
%%
Grammatikregeln
II.3 Grammatikregeln
Wichtigster Bestandteil eines YACC-Quellprogrammes sind die Grammatikregeln. Eine solche Grammatikregel besteht aus einem nicht-terminalen Symbol auf der linken Seite, gefolgt von einem Doppelpunkt (:) in der Mitte und auf der rechten Seite einer oder mehreren Regelalternativen, die durch ein Pipe-Zeichen (|) voneinander getrennt werden. Jede Regelalternative läßt sich auch einzeln (als einzelne Regel) hinschreiben. Diese Regelalternativen bestehen aus einer Aneinanderreihung von weiteren nicht-terminalen und terminalen Symbolen, wobei Literale in Anführungszeichen gesetzt werden und Tokens nach Konvention immer groß geschrieben werden sollten. Der Parser "weiß" dann, daß er eine solche Aneinanderreihung von Symbolen im Tokenstrom zu dem Symbol vor dem Doppelpunkt reduzieren kann. Die Regel wird durch ein Semikolon (;) beendet. Auch die leere Regelalternative ist erlaubt, der Parser kann dann "Nichts" zu einem Symbol reduzieren. Die weiter oben angesprochene Grammatikregel würde also formal lauten:
Ausdruck : ZAHL
| ZAHL Operator ZAHL;
Zu jeder Regelalternative kann man optional noch C-Aktionen angeben, die nach Abarbeitung dieser Regelalternative ausgeführt werden. Diese ganz normalen C-Anweisungen werden einfach in geschweifte Klammern hinter die Regelalternative geschrieben. Dafür stehen auch einige Variablen zur Verfügung, die mit dem Dollarzeichen beginnen. Die Variable $$ bezeichnet den Wert des Symbols, das vor dem Doppelpunkt steht, die Variable $1 bezeichnet den Wert des ersten Symbols der Regelalternative, die Variable $2 den Wert des zweiten Symbols usw. Hier ein etwas komplizierteres Beispiel, die Grammatikregeln für einen einfachen "Taschen"rechner:
%%
Eingabe : /* leer */
| Eingabe Zeile;
Zeile : '\n'
| Ausdruck '\n' { printf("\t%.10g\n", $1; };
Ausdruck : ZAHL { $$ = $1; }
| Ausdruck '+' Ausdruck { $$ = $1 + $3; }
| Ausdruck '-' Ausdruck { $$ = $1 - $3; }
| Ausdruck '*' Ausdruck { $$ = $1 * $2; }
| Ausdruck '/' Ausdruck { $$ = $1 / $2; }
| '(' Ausdruck ')' { $$ = $2; };
Dies bedeutet, eine Eingabe besteht aus "gar nichts" oder einer Eingabe und einer Zeile (d.h. die Symbole Eingabe und Zeile können, wenn sie hintereinander vorkommen, beim Parsing zu dem Symbol Eingabe reduziert werden, genauso wie "gar nichts") . Die Zeile soll den zu berechnenden Ausdruck enthalten. Da der Taschenrechner aber nicht immer schon nach einer Zeile beendet werden soll, wird das übergeordnete Symbol Eingabe eingeführt. Eine Zeile besteht entweder nur aus einem Zeilenendzeichen ('\n') oder einem Ausdruck und einem Zeilenendzeichen. Ein Ausdruck besteht entweder nur aus einer Zahl oder einem Ausdruck, einem Operator (als Literal) und einem weiteren Ausdruck, oder einem geklammerten Ausdruck. Die Zahl ist ein Token, d.h. ein Terminalsymbol, welches nicht weiter durch Regeln beschrieben werden kann.
Man sieht, Symbole können in den Regeln auch rekursiv definiert werden, dies ist sogar sehr häufig der Fall. Es ist dabei natürlich wie bei allen Rekursionen wichtig, daß die Rekursion auch aufgelöst wird. Dies wäre im Beispiel nicht der Fall, wenn die Regelalternative ZAHL in den Regeln für das Symbol Ausdruck fehlen würde.
Hier werden auch zusätzliche C-Aktionen in den Regeln verwendet. Zum Beispiel wird beim erfolgreichen Abarbeiten der Regel für Zeile die Variable $1 (der Wert des ersten Symbols nach dem Doppelpunkt, also hier der Wert von Ausdruck) als Fließkommazahl mit zehn Stellen hinter dem Komma auf dem Bildschirm ausgegeben. Dies bedeutet, es wird das Ergebnis der Berechnung einer Eingabezeile des Taschenrechners ausgeben. Der Wert von Ausdruck wird in den jeweiligen Regeln darunter ausgerechnet: Besteht der Ausdruck nur aus einer Zahl, bekommt Ausdruck mit der Anweisung $$ = $1 den Wert von Zahl. (Hier könnte der Anweisungsteil auch weggelassen werden, da die Zuweisung $$ = $1 bei jeder Regel implizit ausgeführt wird.) Wird die Regelalternative Ausdruck : Ausdruck '+' Ausdruck angewendet, bekommt der neue Ausdruck den Wert des ersten Ausdrucks plus dem Wert des zweiten Ausdrucks (d.h. den Wert des ersten plus dem Wert des dritten Symbols, $$ = $1 + $3), entsprechend bei den anderen Regelalternativen.
Diesen (Zahl-)Wert eines Symbols bekommt der Parser vom Scanner über die globale Variable yylval.
II.4 Deklarationen
Alle Symbole, die nicht durch Grammatikregeln definiert werden und keine Literale sind (also alle Tokens), müssen deklariert werden. Dies geschieht mit dem Schlüsselwort %token in den YACC-Deklarationen. Für das Taschenrechner-Beispiel müßte man wenigstens das Token ZAHL deklarieren:
%token ZAHL
Es lassen sich auch mehrere Tokens auf einmal deklarieren:
%token ZAHL BUCHSTABE
Weitere Definitionsmöglichkeiten für Tokens stehen in Kapitel IV.1 (Links-/Rechts-/Nichtassoziativität von Operatoren).
Außerdem will man vielleicht, daß der Taschenrechner nicht nur mit ganzen Zahlen rechnet, denn der Standard-Datentyp der Tokens in YACC ist Integer. Dieser läßt sich aber mit dem Makro YYSTYPE in den C-Deklarationen festlegen, beispielsweise so:
%{
#define YYSTYPE double
%}
Das Makro YYSTYPE weist den Tokens einen anderen Datentyp zu, in diesem Fall den Typ double. Dies bedeutet, daß der Wert bzw. Inhalt der Tokens, der ja über die Variable yylval angesprochen wird, eine Fließkommazahl ist. Auch C-Include-Anweisungen lassen sich hier angeben.
II.5 Funktionen
Außerdem muß man die angesprochenen Funktionen yylex() und eventuell main() angeben. Sie werden zwar nicht von YACC, aber vom C-Compiler benötigt, wenn man den ausführbaren Parser erzeugen will. Die Funktion main() läßt sich wie schon angesprochen auch über die YACC-Bibliothek (C-Compileroption -ly) einbinden. Die Funktion yylex() läßt sich auch mit LEX entwickeln (siehe Kapitel V). Verzichtet man darauf, schreibt man sie im dritten Teil des YACC-Quellprogrammes nach Deklarationen und Grammatikregeln ganz normal in C hin, zum Beispiel:
/* Grammatik_ */
%%
int yylex ()
{
int c;
while ((c = getchar ()) == ' ' || c == '\t');
if (c == '.' || isdigit (c))
{
ungetc (c, stdin);
scanf ("%1f",&yylval);
return ZAHL;
}
return c;
}
int main ()
{
yyparse;
}
Tokens werden intern als Zahl oberhalb von 255 identifiziert, Literale durch ihren ASCII-Wert (Zahl kleiner oder gleich als 255). Dies ist jedoch normalerweise für den Benutzer von YACC nicht von Belang, da diese Zahlen von YACC automatisch festgelegt werden.
Die Funktion yylex() im obigen Beispiel ignoriert Leerzeichen und Tabulatoren, gibt bei Zahlen das Token ZAHL zurück, schreibt ihren Wert in die globale Variable yylval und gibt alle anderen Zeichen direkt als ASCII-Wert, also als Literal zurück.
II.6 Fehlerbehandlung
Tritt beim Parsing eines Textes ein Fehler auf, bricht der von YACC erzeugte Parser standardmäßig mit der Fehlermeldung "syntax error" ab. Sie wird mit Hilfe der Funktion yyerror() ausgegeben. Diese wird ebenfalls mit der C-Compileroption -ly eingebunden, oder man gibt sie selbst an. Sie könnte dann ganz einfach so aussehen:
yyerror (char *s)
{
printf ("%s\n",s);
}
Diese Verhalten ist bei vielen Anwendungen von YACC aber nicht akzeptabel. Beispielsweise ist bei unserem Taschenrechner nicht erwünscht, daß er nach einer fehlerhaften Eingabe einfach abbricht, sondern er sollte nach Erkennung des Fehler seine Arbeit wieder aufnehmen und eine neue Eingabe zulassen. Genau das bewirkt die folgende Erweiterung der Grammatikregel für Zeile:
...
Zeile : '\n'
| Ausdruck '\n'{ printf("\t%.10g\n", $1; }
| error '\n' { yyerrok };
...
Es wird einfach eine neue Regelalternative eingefügt, die in Kraft tritt, falls das vordefinierte Token error und ein Zeilenendzeichen auftritt. Error bedeutet, beim Parsing des Tokenstromes ist ein Fehler aufgetreten. Wenn der Parser beispielsweise auf den Tokenstrom Ausdruck '+' '+' '\n' trifft, erfüllt Ausdruck '+' '+' keine Grammatikregeln und wird deshalb zu dem Token error reduziert. Dann wird die YACC-Funktion yyerrok() aufgerufen. Diese ruft die Funktion yyerror() auf, um die Fehlermeldung auszugeben, und kehrt dann wieder vor das zuletzt eingelesene Token oder Literal zurück, ohne den Parser abzubrechen. Das zuletzt eingelesene Literal ist dann '\n', welches eine Regelalternative für Zeile erfüllt.
Es ist jedoch nicht gleichgültig, wo man yyerrok() verwendet. Plaziert man es falsch, tritt im günstigsten Fall nicht die gewünschte Wirkung ein, im ungünstigsten Fall setzt der Parser an einer Stelle auf, die wieder einen Fehler produziert und so eine Endlosschleife produziert. Setzt man die Anweisung yyerrok() beispielsweise direkt hinter error (also ohne weitere Literale oder Tokens), wird nach Ausf"hrung von yyerrok() wieder direkt vor error aufgesetzt, wodurch wiederum yyerrok() aufgerufen wird usw. Man kann jedoch yyerrok auch in eine andere Regelalternative schreiben, wenn man sicher ist, daß dort wieder fehlerfrei aufgesetzt werden kann.
Leider ist es auch nicht so einfach möglich, den Text der Fehlermeldung zu ändern oder von der jeweiligen Situation abhängige Fehlermeldungen auszugeben. Diese Änderungen müßte man "von Hand" in der vom YACC erzeugten Funktion yyparse() vornehmen, in manchen Fällen sogar in main(). Dies ist natürlich sehr umständlich, und darauf einzugehen würde hier den Rahmen sprengen. Meiner Meinung nach ist dieser Mangel eine echte Schwäche von YACC.
III. Wie funktioniert der von Yacc erzeugte Parser?
III.1 Ablauf
Der Parser arbeitet mit einem Stack, Operationen auf diesem Stack und Zuständen, die auf diesem Stack abgelegt werden. Parallel dazu wird ein Wertestack angelegt, der die (Zahl-)Werte der Symbole aufnimmt. Die wichtigsten Operationen auf dem Stack sind die shift- und die reduce-Operation, daneben gibt es auch noch die Operationen goto, accept und error.
Bei einer shift-Operation wird das Vorgriffs-Token gelesen und der daraus resultierende neue Zustand auf den Stack gelegt. Danach wird das Vorgriffs-Token gelöscht.
Eine reduce-Operation wird ausgeführt, wenn der Parser eine Grammatikregel gefunden hat, die auf den aktuellen Zustand paßt, unter Umständen muß dazu noch das Vorgriffs-Token abgefragt werden. Dann wird die rechte Seite der Regel durch die linke Seite ersetzt, d.h. der Zustand auf dem Stack wird geändert.
Eine goto-Operation bewirkt, daß ein neuer Zustand auf den Stack gelegt wird, ähnlich wie bei einer shift-Operation. Das Vorgriffs-Token wird jedoch nicht gelöscht.
Für den Fall, daß ein Fehler auftritt, d.h. wenn der Parser feststellt, daß er die Eingabe-Tokens nicht nach Spezifikation abarbeiten kann, gibt es die error-Operation. Diese führt zu einer Fehlermeldung, wie in Kapitel II.6 beschrieben.
Wenn kein Fehler gefunden wurde und das Vorgriffs-Token die Endemarkierung $end (Token '\0') enthält, wird die accept-Operation ausgeführt.
In der folgenden Tabelle werden die Zustände auf dem Stack durch die verarbeiteten Symbole repräsentiert. Als Vereinfachung wird die goto-Operation nicht berücksichtigt. Die Spalte "Schritt" gibt die nächste Operation an, die Spalte "Regel" die Grammatikregel, nach der im nächsten Schritt reduziert wird. In der Spalte "Wertestack" wird der Inhalt des Wertestacks angegeben. Das Lattenkreuz (#) bedeutet dabei, daß für das entsprechende Symbol (z.B. Operatoren und andere Literale) kein Wert in yylval übergeben wird, d.h. yylval unbestimmt ist. Das Größer-Zeichen (>) gibt (nur bei reduce-Operationen) die Position an, ab der in den Regeln mit den Variablen $1, $2 usw. auf den Wertestack zugegriffen werden kann. Der Parse-Vorgang der Eingabe "3 * ( 4 + 2 ) \n", also "ZAHL '*' '(' ZAHL '+' ZAHL ')' '\n' ", würde folgendermaßen verlaufen:
| Stack | Tokenstring der Eingabe | Regel | Schritt | Wertestack |
|---|---|---|---|---|
| ZAHL '*' '(' ZAHL '+' ZAHL ')' '\n' $end | shift | 0 | ||
| ZAHL | '*' '(' ZAHL '+' ZAHL ')' '\n' $end | 5 | reduce | 0,> 3 |
| Ausdruck | '*' '(' ZAHL '+' ZAHL ')' '\n' $end | shift | 0,3 | |
| Ausdruck '*' | '(' ZAHL '+' ZAHL ')' '\n' $end | shift | 0,3,# | |
| Ausdruck '*' '(' | ZAHL '+' ZAHL ')' '\n' $end | shift | 0,3,#,# | |
| Ausdruck '*' '(' ZAHL | '+' ZAHL ')' '\n' $end | 5 | reduce | 0,> 4 |
| Ausdruck '*' '(' Ausdruck | '+' ZAHL ')' '\n' $end | shift | 0,3,#,#,4 | |
| Ausdruck '*' '(' Ausdruck '+' | ZAHL ')' '\n' $end | shift | 0,3,#,#,4,# | |
| Ausdruck '*' '(' Ausdruck '+' ZAHL | ')' '\n' $end | 5 | reduce | 0,3,#,#,4,#,> 2 |
| Ausdruck '*' '(' Ausdruck '+' Ausdruck | ')' '\n' $end | 6 | reduce | 0,3,#,#,> 4,#,2 |
| Ausdruck '*' '(' Ausdruck | ')' '\n' $end | shift | 0,3,#,#,6 | |
| Ausdruck '*' '(' Ausdruck ')' | '\n' $end | 10 | reduce | 0,3,#,> #,6,# |
| Ausdruck '*' Ausdruck | '\n' $end | 8 | reduce | 0,> 3,#,6 |
| Ausdruck | '\n' $end | shift | 0,18 | |
| Ausdruck '\n' | $end | 4 | reduce | 0,> 18,# |
| Zeile | $end | 2 | reduce | 0,> 18 |
| Eingabe Zeile | $end | 1 | reduce | 0 |
| Eingabe $end | accept | 0 |
Zuerst wird das erste Token ZAHL auf den Stack geshiftet. Diese kann dann nach Grammatikregel 5 zu einem Ausdruck reduziert werden. Dann werden wieder Tokens geshiftet, bis wieder eine ZAHL zu Ausdruck reduziert werden kann. Dies geht dann so weiter bis in Zeile 10, wo Ausdruck '+' Ausdruck nach Grammatikregel zu einem Ausdruck reduziert wird. Besonders interessant ist auch noch Zeile 16, wo "Nichts" nach Grammatikregel 1 zu einer Eingabe reduziert wird. In Zeile 18 ist die Syntaxerkennung dann abgeschlossen. Das Vorgriffs-Token enthält zwar schon vorher $end, es wird jedoch erst wieder in Zeile 18 abgefragt. Dies hängt mit der Implementierung des Parsers in Zuständen ab, die im nächsten Abschnitt erläutert wird.
III.2 Die Datei y.output
Die Datei y.output läßt sich mit der YACC-Option -v erzeugen. Sie enthält alle möglichen Zustände, die der Parser annehmen kann. Zu jedem Zustand werden die sogenannte Konfiguration (die Zustandsbeschreibung), die verfügbaren Operationen und die Operationen, die im Falle einer Reduzierung ausgeführt werden, beschrieben. Dies ist nützlich, um zu verstehen, wie der erzeugte Parser funktioniert, zum Beispiel zur Fehlersuche oder zum allgemeinen Verständnis, denn aus dieser Datei läßt sich der tatsächliche Ablauf beim Parsen eines Ausdrucks rekonstruieren.
Zu der Beispiel-Grammatik
%token IDENTIFIER
%%
expression : expression '-' IDENTIFIER
| IDENTIFIER
erzeugt YACC die folgende Datei y.output:
state 0
$accept : _expression $end
IDENTIFIER shift 2
. error
expression goto 1
state 1
$accept : expression_$end
expression : expression_-IDENTIFIER
$end accept
- shift 3
. error
state 2
expression : IDENTIFIER_ (2)
. reduce 2
state 3
expression : expression -_IDENTIFIER
IDENTIFIER shift 4
. error
state 4
expression : expression - IDENTIFIER_ (1)
. reduce 1
Der Zustand ("state") 0 ist immer der Startzustand, und er enthält immer das Startsymbol. Die Zeile "$accept : _expression $end" beschreibt die Konfiguration: Der Unterstrich (_) zeigt die aktuelle Position der Abarbeitung an, also vor der Erkennung einer expression. Mögliche Operation ist hier in dem Falle, daß das Vorgriffs-Token einen IDENTIFIER enthält eine shift-Operation zu dem Zustand 2, sonst eine error-Operation. Zustand 2 ist nach Erkennung eines IDENTIFIERS. Hier ist die einzig-mögliche Operation ein reduce nach Regel 2. Danach wird wieder in Zustand 0 zurückgesprungen, wo als nächstes, da etwas zu einer expression reduziert wurde, mit einer goto-Operation Zustand 1 auf den Stack gelegt wird. So geht es weiter, bis die gesamte Eingabe abgearbeitet ist, wie in der folgenden Tabelle für die Eingabe IDENTIFIER '-' IDENTIFIER ausgeführt ist:
| Schritt | Stack (Zustand) | Vorgriffs-Token | Operation |
|---|---|---|---|
| 1 | 0 | IDENTIFIER | shift 2 |
| 2 | 0,2 | reduce 2 | |
| 3 | 0 | goto 1 | |
| 4 | 0,1 | - | shift 3 |
| 5 | 0,1,3 | IDENTIFIER | shift 4 |
| 6 | 0,1,3,4 | reduce 1 | |
| 0,1 | $end | accept |
IV. Mehrdeutigkeiten und Konflikte
IV.1. Links-/Rechts-/Nichtassoziativität von Operatoren
Oft ist es wünschenswert, die Assoziativität von Tokens bzw. Operatoren, also die "Bindung" zu definieren. Bei unserem Beispiel, dem Taschenrechner, gibt es beispielsweise den Operator "/" (geteilt). Wenn er in einer Eingabe mehrfach hintereinander vorkommt, wie zum Beispiel in "1 / 2 / 3", ist nicht klar, ob hier "(1 / 2) / 3" oder "1 / (2 / 3)" gemeint ist. Üblicherweise meint man, wenn man keine Klammern explizit angibt, die erste Alternative. Diese ist linksassoziativ, da zuerst das linke und dann erst das rechte Geteiltzeichen ausgewertet wird. In einer YACC-Grammatik erreicht man diese Art der Auswertung durch die Deklaration %left '/' (allgemein %left TOKEN bzw. %left LITERAL). Entsprechend wird Rechtsassoziativität mit %right TOKEN bzw. %right LITERAL deklariert. Außerdem ist es möglich, Tokens als nichtassoziativ zu deklarieren (%unassoc TOKEN bzw. %unassoc LITERAL). Dies ist zum Beispiel bei Vergleichsoperatoren in Programmiersprachen sinnvoll. Die Eingabe "x < y < 4" wäre dann ungültig und würde eine entsprechende Fehlermeldung bewirken. Wenn man keine Assoziativität angibt (also z.B. nur %token), wird rechtsassoziativ ausgewertet.
IV.2. Priorität von Operatoren
Bei dem Taschenrechnerbeispiel tritt noch ein weitere Problem auf: Das der Priorität der Operatoren. Die Eingabe "1+2*3" könnte sowohl als "1+(2*3)" als auch als "(1+2)*3" ausgewertet werden. Um die übliche Regel "Punktrechnung vor Strichrechnung" zu erreichen, muß man für eine korrekte Deklaration der YACC-Grammatik sorgen. Die Rangfolge von Operatoren (also für den Parser die Reihenfolge der Auswertung von Tokens) wird definiert durch die Reihenfolge der Deklaration in der YACC-Grammatik. Je weiter hinten in der Grammatik ein Token deklariert wird, desto größer ist seine Priorität. Beispielsweise würde durch die Deklaration
%left '+' '-'
%left '*' '/'
die bekannte Punktrechnung vor Strichrechnung erreicht werden, und die Operatoren werden gleichzeitig alle als linksassoziativ definiert.
Manchmal tritt das Problem auf, das ein Literal als Zeichen für verschieden Operatoren eingesetzt wird. Das "-" (Minus)-Zeichen wird zum Beispiel sowohl für die Subtraktion als auch für Negierung verwendet. Will man für die Operationen verschiedene Priorität definieren, wird eine kontext-abhängige Priorität notwendig. Dies läßt sich in YACC für das Beispiel (und auch allgemein) folgendermaßen lösen:
...
%left '+' '-'
%left '*' '/'
%left NEG
%%
...
| Ausdruck '/' Ausdruck { $$ = $1 / $2; }
| '-' Ausdruck %prec NEG { $$ = -$2 }
| '(' Ausdruck ')' { $$ = $2; };
Hier wird das Hilfstoken NEG eingeführt, das eine höhere Priorität als alle andere Operatoren hat. In der Grammatikregel für die Negierung bekommt diese durch das Schlüsselwort %prec (für engl. "precedence") dieselbe Priorität wie NEG zugewiesen.
IV.3. reduce/shift - Konflikte
Ein weiterer Konflikttyp tritt beispielsweise in folgender (unvollständigen) Beispiel-Grammatik auf:
if_statement: IF expression THEN statement
| IF expression THEN statement ELSE statement;
Bei der Eingabe
if x then if y then win ; else lose;
gibt es für den Parser zwei Möglichkeiten, nach Abarbeitung von if y then win vorzugehen:
- Der Parser könnte die erste Regel anwenden und eine reduce-Operation durchführen. In dem Beispiel würde also else zu dem äußeren if x then ... gehören.
- Der Parser könnte aber auch die zweite Regel anwenden und eine shift-Operation durchführen. In dem Beispiel würde also else zu dem inneren if y then win gehören.
IV.4. reduce/reduce - Konflikte
Auch in der folgenden (unvollständigen) Beispiel-Grammatik gibt es einen Konflikt:
satz : /* leer */
| vielleichtwort
| satz wort;
vielleichtwort : /* leer */
| wort;
Hier gibt es für den Parser zwei Möglichkeiten, ein wort zu parsen:
- entweder kann der Parser ein wort zu einem vielleichtwort und dann zu einem satz reduzieren,
- oder der Parser kann "nichts" zu einem satz reduzieren, und diesen zusammen mit dem wort wieder zu einem satz reduzieren.
satz : /* leer */
| satz wort;
In diesem Beispiel scheint das trivial zu sein, da normalerweise sowieso niemand die erste Lösung verwenden würde. In komplizierteren Fällen kann es jedoch auch bei diesem Konflikt schwierig werden.
V. Zusammenarbeit mit dem Scanner Lex
Anstatt die Funktion yylex() in C "von Hand" selbst zu schreiben, bietet es sich gerade bei Scannern, die etwas mehr leisten sollen, an, sie mit Hilfe von LEX zu erstellen.
LEX erzeugt aus der LEX-Quelldatei (vgl. den Vortrag zu LEX) die Datei lex.yy.c, die die schon besprochene Funktion yylex(), den Scanner, enthält. Diesen sollte man mit der C-Anweisung #include "lex.yy.c" in den Funktionsteil der YACC-Grammatik einbinden. Alternativ kann man die Include-Anweisung auch weglassen, dann muß man jedoch beim compilieren auch den von LEX erzeugten C-Quelltext angeben. Die Vorgehensweise ist also: Man erzeugt den Scanner mit LEX, den eigentlichen Parser mit YACC, und compiliert alles mit einem C-Compiler zu dem fertigen Parser (siehe auch Abbildung ), also zum Beispiel so:
lex taschenrechner.x
yacc taschenrechner.y
cc y.tab.c -ly -ll bzw. cc y.tab.c lex.yy.c -ly -ll
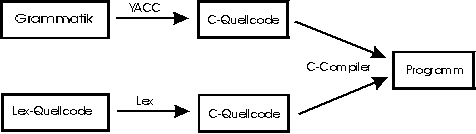
Die C-Compileroption -ll bindet die LEX-Standardbibliothek in das Programm mit ein.
Ein LEX-Programm, das den Scanner für unseren Taschenrechner beschreibt, könnte beispielsweise so aussehen:
%%
[0-9]+ {yylval = atoi(yytext);
return NUMBER;}
[ \t]+ ;
. return(yytext[0]);
(Anmerkung: Dieser Scanner kann keine Fließkommazahlen einlesen. Ein LEX-Programm, welches das leistet, findet sich z.B. in [4] auf Seite 72)
Anhang A: Die Taschenrechnergrammatik komplett
%{
#include <ctype.h>
#include <stdio.h>
#define YYSTYPE double
%}
%token ZAHL
%left '+' '-'
%left '*' '/'
%left NEG
%%
Eingabe : /* leer */
| Eingabe Zeile;
Zeile : '\n'
| Ausdruck '\n' { printf("\t%.10g\n", $1;}
| error '\n' { yyerrok };
Ausdruck : ZAHL { $$ = $1; }
| Ausdruck '+' Ausdruck { $$ = $1 + $3; }
| Ausdruck '-' Ausdruck { $$ = $1 - $3; }
| Ausdruck '*' Ausdruck { $$ = $1 * $2; }
| Ausdruck '/' Ausdruck { $$ = $1 / $2; }
| '(' Ausdruck ')' { $$ = $2; };
%%
#include "lex.yy.c"
Anhang B: Quellenangaben
- Gottfried Staubach. Unix-Werkzeuge zur Textmusterverarbeitung. Springer, 1989.
- Charles Donelly and Richard M. Stallman. Bison - the YACC-compatible parser generator. Program
- Documentation, version 1.20, Free Software Foundation, December 1992.
- Alfred V. Aho, Ravi Sethi, and Jeffrey D. Ullman. Compiler: Principles, Techniques, and Tools. Addison Wesley, 1986.
- A.-T. Schreiner and M. G. Friedmann. Compiler Bauen mit Unix - Eine Einfhrung. Carl Hanser, Mnchen, 1985.
© 1996, 2004 Eike Meinders